Publications
Last modified: November 2020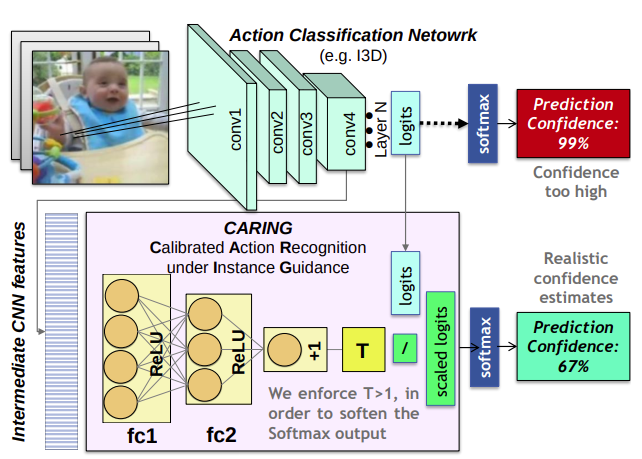
Uncertainty-sensitive Activity Recognition: A Reliability Benchmark and the CARING Models
Alina Roitberg, Monica Haurilet, Manuel Martinez, Rainer Stiefelhagen
International Conference on Pattern Recognition
(ICPR),
Online,
October 2020.
[paper]
[bibtex]
author = {Alina Roitberg and Monica Haurilet and Manuel Martinez and Rainer Stiefelhagen},
title = {{Uncertainty-sensitive Activity Recognition: A Reliability Benchmark, and the CARING Models}},
year = {2020},
month = {October},
booktitle = {International Conference on Pattern Recognition (ICPR)},
}
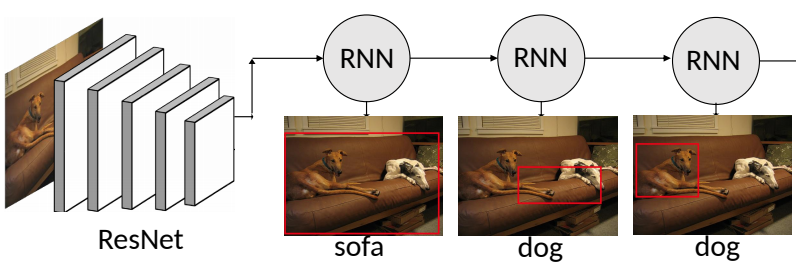
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen
International Conference on Pattern Recognition
(ICPR),
Online,
October 2020.
[paper]
[abstract]
[arxiv]
[bibtex]
author = {Amine Kechaou and Manuel Martinez and Monica Haurilet and Rainer Stiefelhagen},
title = {{Detective: An Attentive Recurrent Model for Sparse Object Detection}},
year = {2020},
month = {October},
booktitle = {International Conference on Pattern Recognition (ICPR)},
}

Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Robin Ruede, Verena Heusser, Lukas Frank, Alina Roitberg, Monica Haurilet, Rainer Stiefelhagen
International Conference on Pattern Recognition
(ICPR),
Online,
October 2020.
[bibtex]
author = {Robin Ruede and Verena Heusser and Lukas Frank and Alina Roitberg and Monica Haurilet and Rainer Stiefelhagen},
title = {{Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information}},
year = {2020},
month = {October},
booktitle = {International Conference on Pattern Recognition (ICPR)},
}
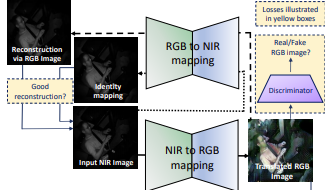
Deep Classification-driven Domain Adaptation for Cross-Modal Behavior Recognition
Simon Reiss*, Alina Roitberg*, Monica Haurilet, Rainer Stiefelhagen
Intelligent Vehicles
(IV),
Online,
October 2020.
[paper]
[bibtex]
author = {Simon Rei\ss* and Alina Roitberg* and Monica Haurilet and Rainer Stiefelhagen},
title = {{Deep Classification-driven Domain Adaptation for Cross-Modal Behavior Recognition}},
year = {2020},
month = {October},
booktitle = {Intelligent Vehicles (IV)},
note = {*equal contribution}
}
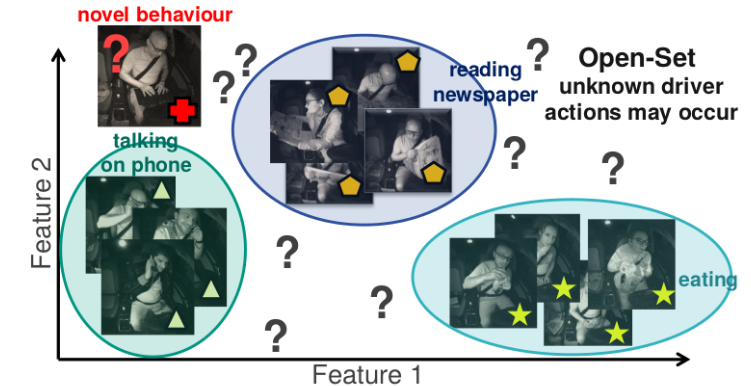
Open Set Driver Activity Recognition
Alina Roitberg, Chaoxiang Ma, Monica Haurilet, Rainer Stiefelhagen
Intelligent Vehicles
(IV),
Online,
October 2020.
[paper]
[bibtex]
2nd Place "Best Student Paper Award"
author = {Alina Roitberg and Chaoxiang Ma and Monica Haurilet and Rainer Stiefelhagen},
title = {{Open Set Driver Activity Recognition}},
year = {2020},
month = {October},
booktitle = {Intelligent Vehicles (IV)}
}

Bring the Environment to Life: Sonifying Fine-Grained Localized Objects for Persons with Visual Impairments
Angela Constantinescu, Karin Mueller, Monica Haurilet, Vanessa Petrausch, Rainer Stiefelhagen
International Conference on Multimodal Interaction
(ICMI),
Online,
October 2020.
[paper]
[bibtex]
author = {Angela Constantinescu and Karin Mueller and Monica Haurilet and Vanessa Petrausch and Rainer Stiefelhagen},
title = {{Bring the Environment to Life: Sonifying Fine-Grained Localized Objects for Persons with Visual Impairments}},
year = {2020},
month = {October},
booktitle = {International Conference on Multimodal Interaction (ICMI)},
}
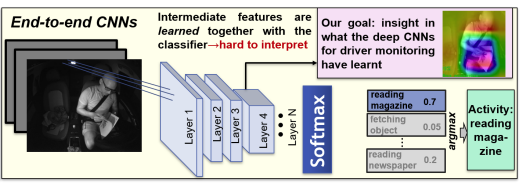
CNN-based Driver Activity Understanding: Shedding Light on Deep Spatiotemporal Representations
Alina Roitberg, Monica Haurilet, Simon Reiss, Rainer Stiefelhagen
International Conference on Intelligent Transportation Systems
(ITSC),
Online,
September 2020.
[paper]
[bibtex]
author = {Alina Roitberg and Monica Haurilet and Simon Reiss and Rainer Stiefelhagen},
title = {{CNN-based Driver Activity Understanding: Shedding Light on Deep Spatiotemporal Representations}},
year = {2020},
month = {September},
booktitle = {International Conference on Intelligent Transportation Systems (ITSC)},
}
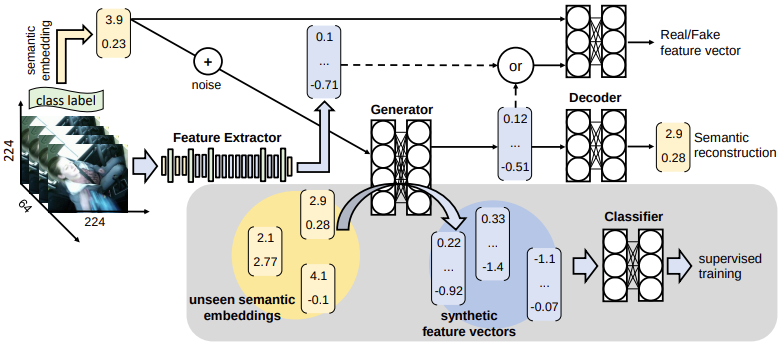
Activity-aware Attributes for Zero-Shot Driver Behavior Recognition
Simon Reiss*, Alina Roitberg*, Monica Haurilet, Rainer Stiefelhagen
CVPRW on Visual Learning with Limited Labels
(VL-LL),
Online,
June 2020.
[paper]
[bibtex]
author = {Simon Reiss and Alina Roitberg and Monica Haurilet and Rainer Stiefelhagen},
title = {{Activity-aware Attributes for Zero-Shot Driver Behavior Recognition}},
year = {2020},
month = {June},
booktitle = {CVPRW on Visual Learning with Limited Labels (VL-LL)},
}
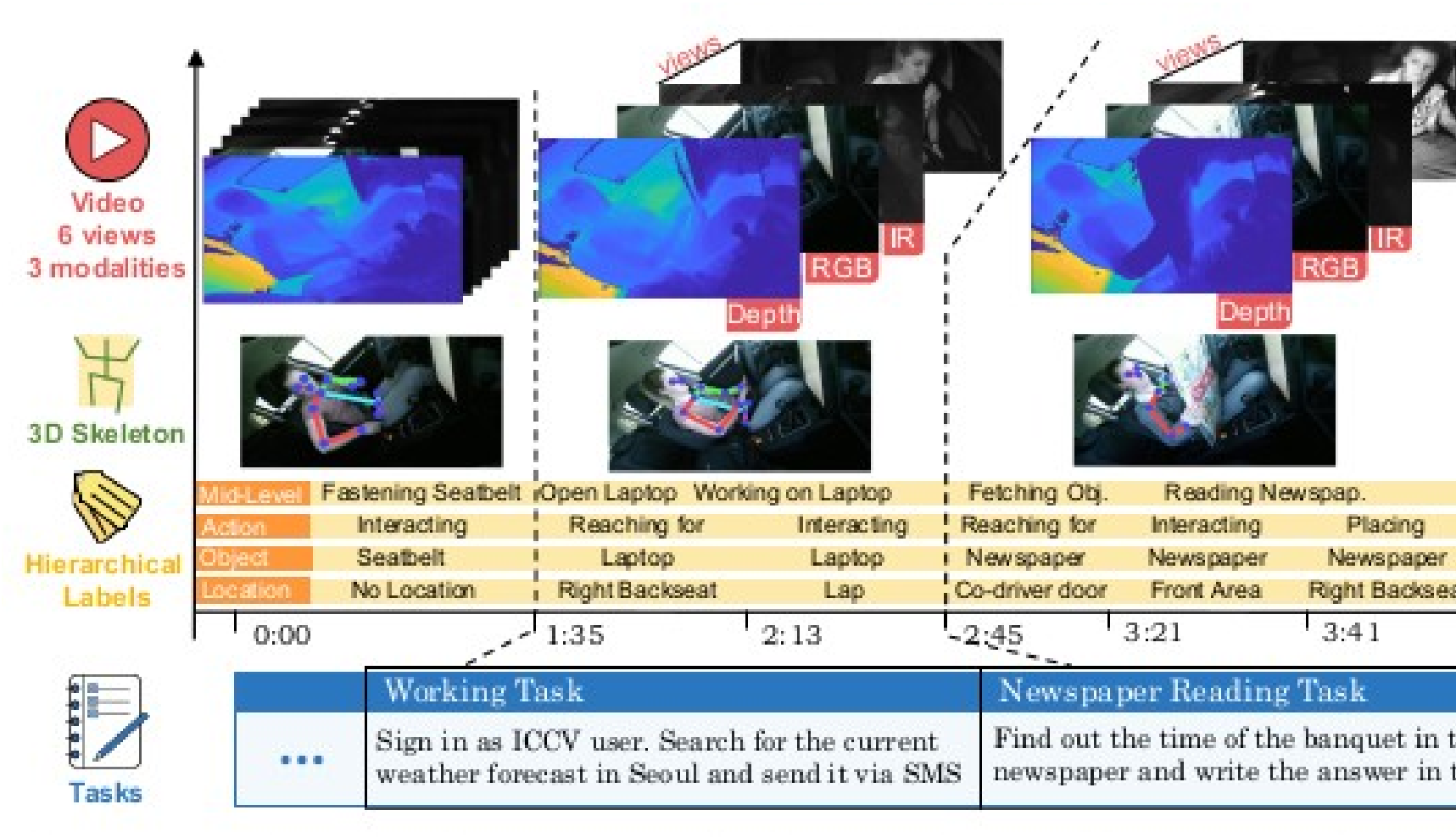
Drive&Act: A Multi-modal Dataset for Fine-grained Driver Behavior Recognition in Autonomous Vehicles
Manuel Martin*, Alina Roitberg*, Monica Haurilet, Matthias Horne, Simon Reiß, Michael Voit, Rainer Stiefelhagen
International Conference on Computer Vision
(ICCV),
Seoul, South Korea,
October 2019.
[paper]
[abstract]
[website]
[bibtex]
author = {Manuel Martin* and Alina Roitberg* and Monica Haurilet and Matthias Horne and Simon Rei\ss and Michael Voit and Rainer Stiefelhagen},
title = {{Drive\&Act: A Multi-modal Dataset for Fine-grained Driver\\ Behavior Recognition in Autonomous Vehicles}},
year = {2019},
booktitle = {International Conference on Computer Vision (ICCV)},
publisher = {IEEE},
month = {October},
note = {*equal contribution}
}
WiSe - Slide Segmentation in the Wild
Monica Haurilet, Alina Roitberg, Manuel Martinez, Rainer Stiefelhagen
International Conference on Document Analysis and Recognition
(ICDAR),
Sydney, Australia,
September 2019.
[paper]
[poster]
[abstract]
[bibtex]
[website]
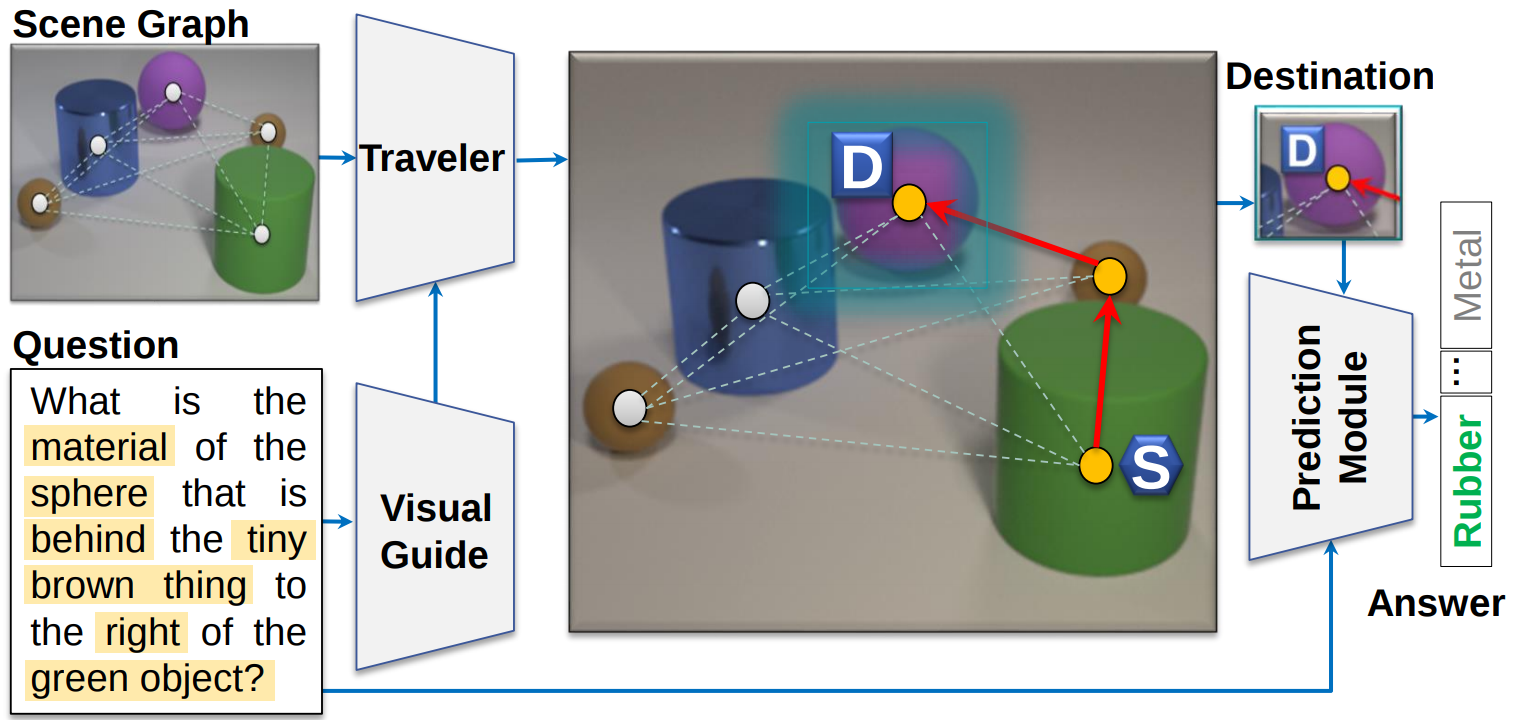
It’s not about the Journey; It’s about the Destination:
Following Soft Paths under Question-Guidance for Visual Reasoning
Monica Haurilet, Alina Roitberg, Rainer Stiefelhagen
Conference on Computer Vision and Pattern Recognition
(CVPR),
Long Beach, USA,
June 2019.
[paper]
[supp.]
[poster]
[abstract]
[download_graphs]
[bibtex]
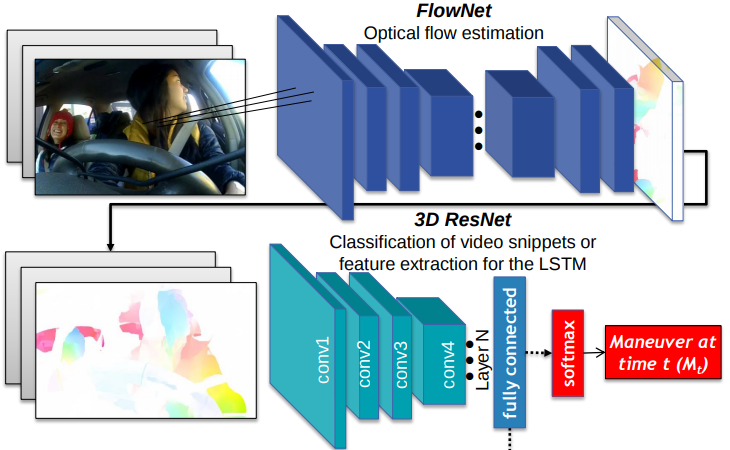
End-to-end Prediction of Driver Intention using 3D Convolutional Neural Networks
Patrick Gebert*, Alina Roitberg*, Monica Haurilet and Rainer Stiefelhagen
Intelligent Vehicles Symposium (IV),
IEEE, Paris, France, 2019.
[paper]
[bibtex]
author = {Patrick Gebert* and Alina Roitberg* and Monica Haurilet and Rainer Stiefelhagen},
title = {{End-to-end Prediction of Driver Intention using 3D Convolutional Neural Networks}},
booktitle = {Intelligent Vehicles Symposium (IV)},
publisher = {IEEE},
year = {2019},
month = {June},
address = {Paris, France},
note = {*equal contribution}
}
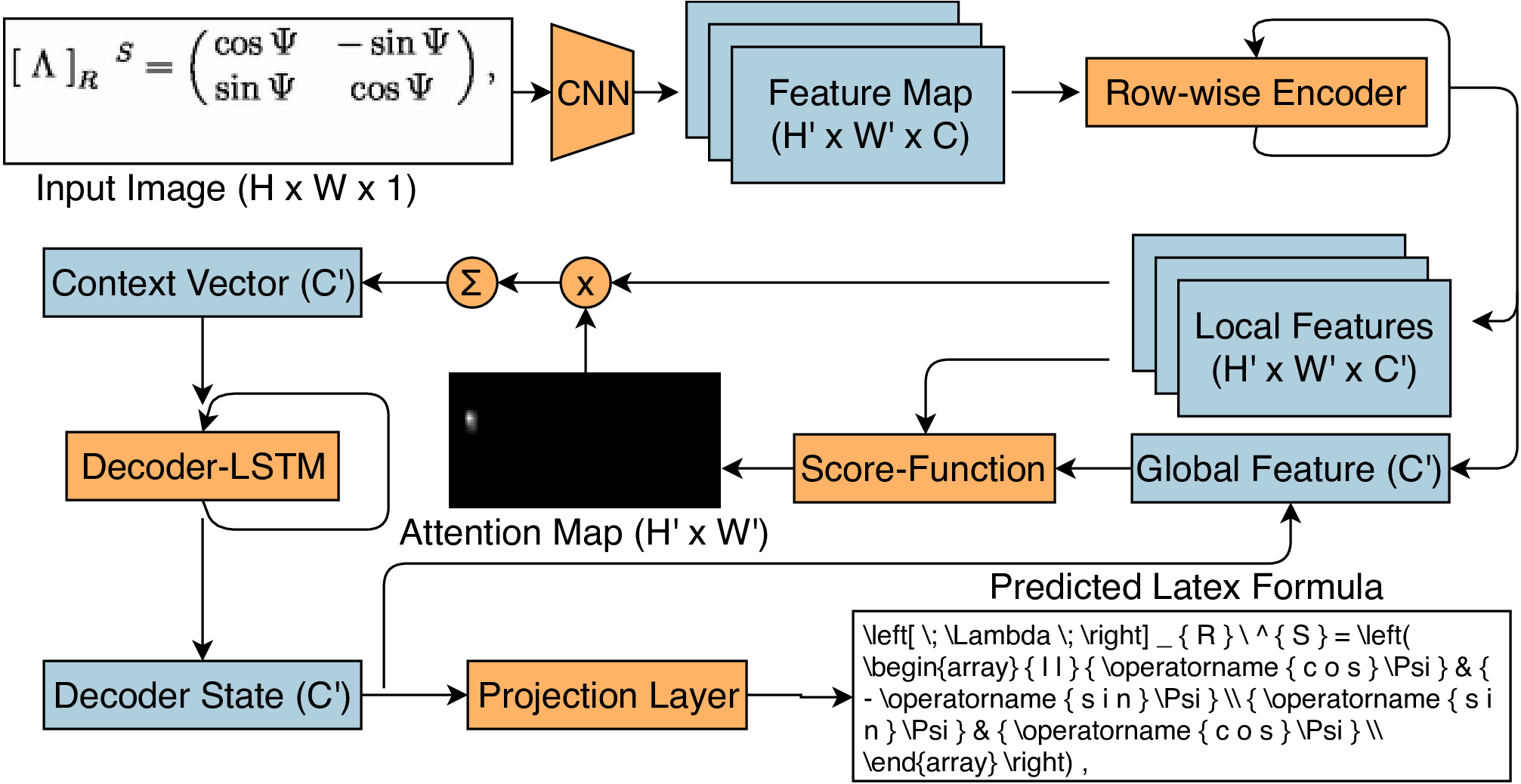
Learning Fine-Grained Image Representations for Mathematical Expression Recognition
Sidney Bender*, Monica Haurilet*, Alina Roitberg, Rainer Stiefelhagen
ICDARW on Graphics Recognition
(GREC),
Sydney, Australia, 2019.
[paper]
[slides]
[bibtex]
}

Analysis of Deep Fusion Strategies for Multi-modal Gesture Recognition
Alina Roitberg*, Tim Pollert*, Monica Haurilet, Manuel Martin, Rainer Stiefelhagen
CVPRW on Analysis and Modeling of Faces and Gestures (AMFG),
IEEE, Long Beach, USA, 2019.
[paper]
[bibtex]
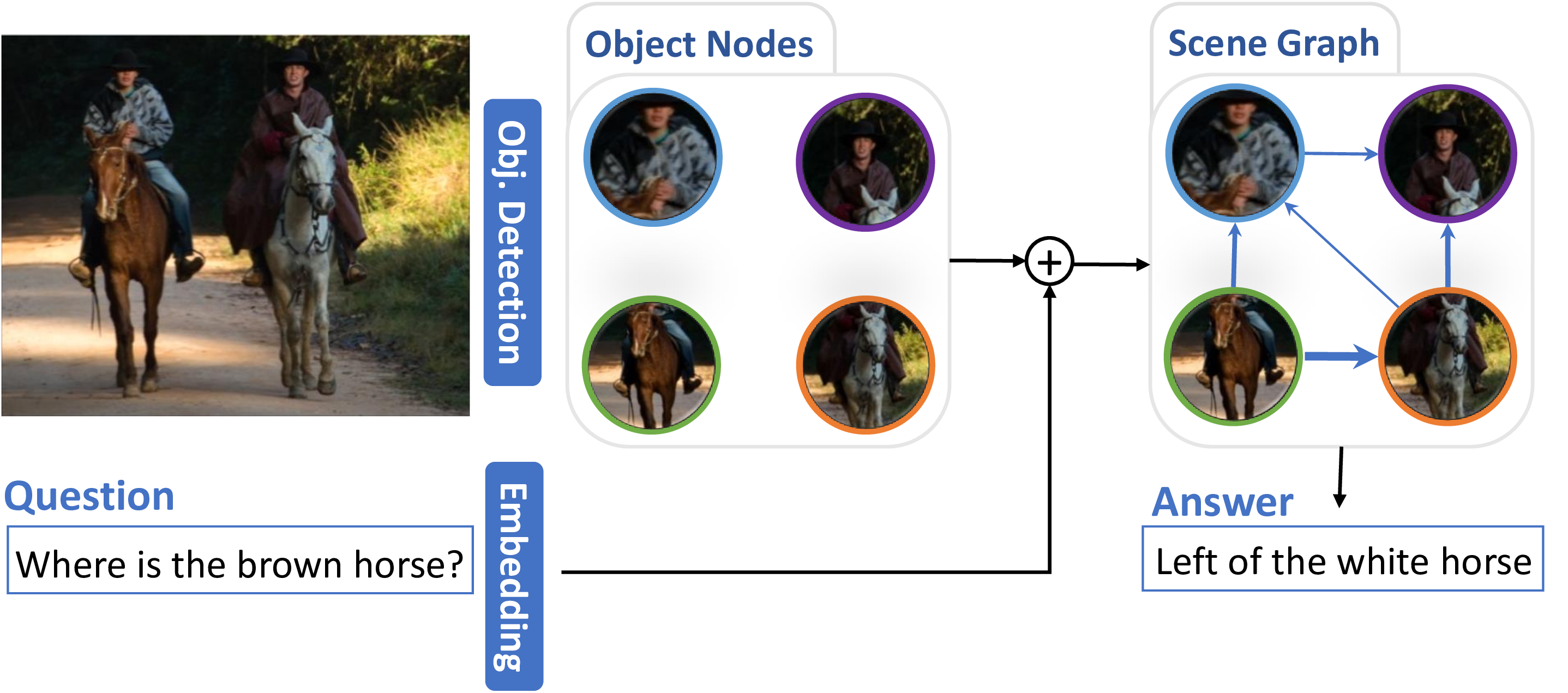
DynGraph: Visual Question Answering via Dynamic Scene Graphs
Monica Haurilet, Ziad Al-Halah, Rainer Stiefelhagen
German Conference on Pattern Recognition
(GCPR),
Dortmund, Germany, 2019.
[bibtex]
}
SPaSe - Multi-Label Page Segmentation for Presentation Slides
Monica Haurilet, Ziad Al-Halah, Rainer Stiefelhagen
Winter Conference on Applications of Computer Vision
(WACV),
Waikoloa, Hawaii, USA,
Jan. 2019.
[paper]
[supp.]
[abstract]
[website]
[slides]
[bibtex]
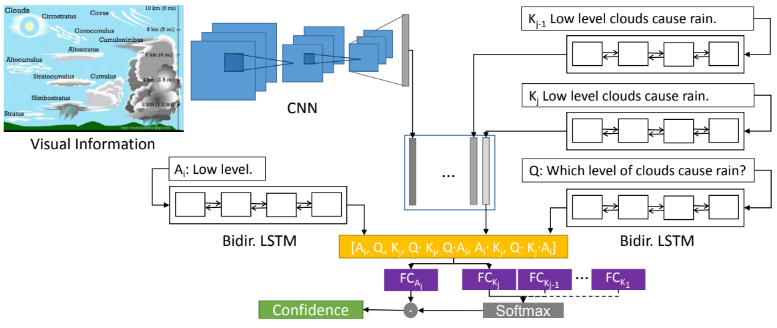
MoQA - A Multi-Modal Question Answering Architecture
Monica Haurilet, Ziad Al-Halah, Rainer Stiefelhagen
ECCVW on Shortcomings in Vision and Language
(SiVL
Spotlight),
Munich, Germany, 2018.
[paper]
[bibtex]
[poster]
[slides]
Winner of the TQA challenge
author = {Monica Haurilet and Ziad Al-Halah, Rainer Stiefelhagen},
title = {{MoQA - A Multi-Modal Question Answering Architecture}},
booktitle = {ECCV Workshop on Shortcomings in Vision and Language (SiVL)},
publisher = {Springer},
year = {2018},
month = {September},
address = {Munich, Germany}
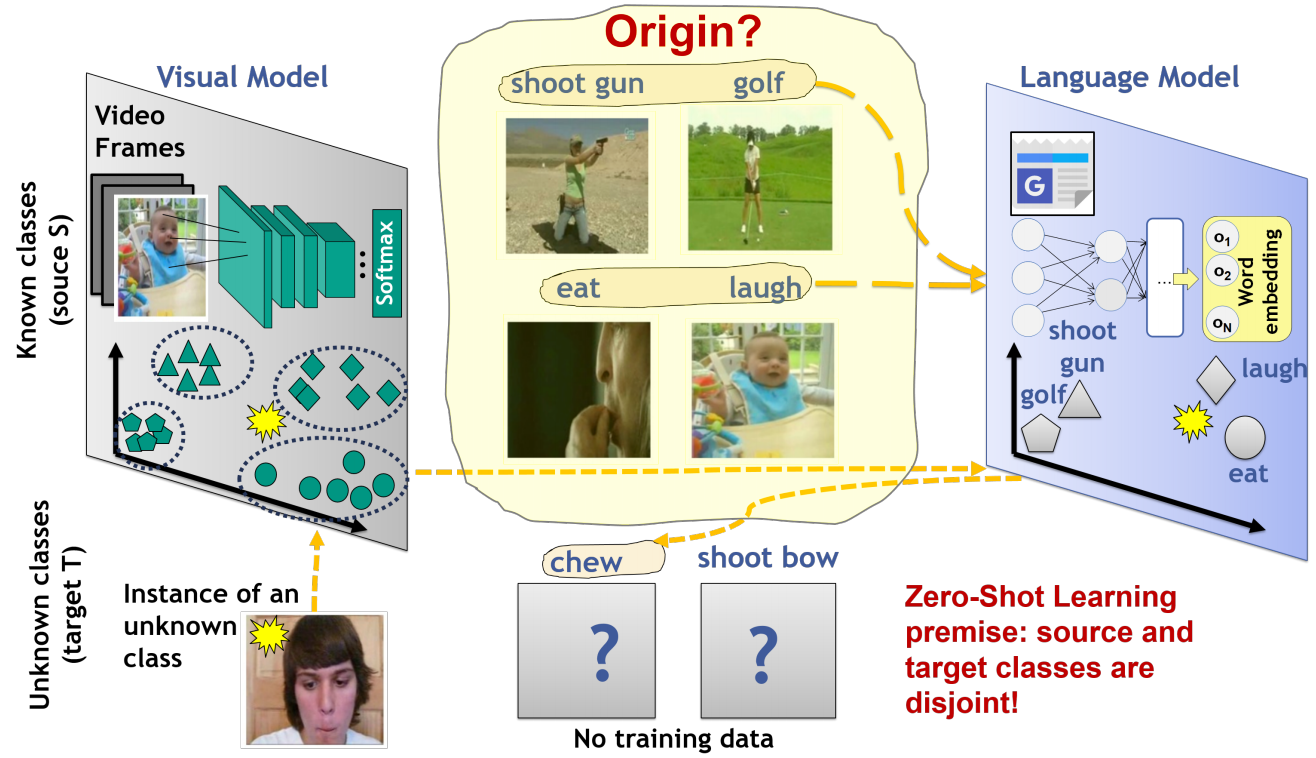
Towards a Fair Evaluation of Zero-Shot Action Recognition using External Data
Alina Roitberg, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen
ECCVW on Shortcomings in Vision and Language
(SiVL
Spotlight),
Munich, Germany, 2018.
[paper]
[bibtex]
[poster]
[slides]
author = {Alina Roitberg and Manuel Martinez and Monica Haurilet and Rainer Stiefelhagen},
title = {{Towards a Fair Evaluation of Zero-Shot Action Recognition using External Data}},
booktitle = {ECCV Workshop on Shortcomings in Vision and Language (SiVL)},
publisher = {Springer},
year = {2018},
month = {September},
address = {Munich, Germany} } }
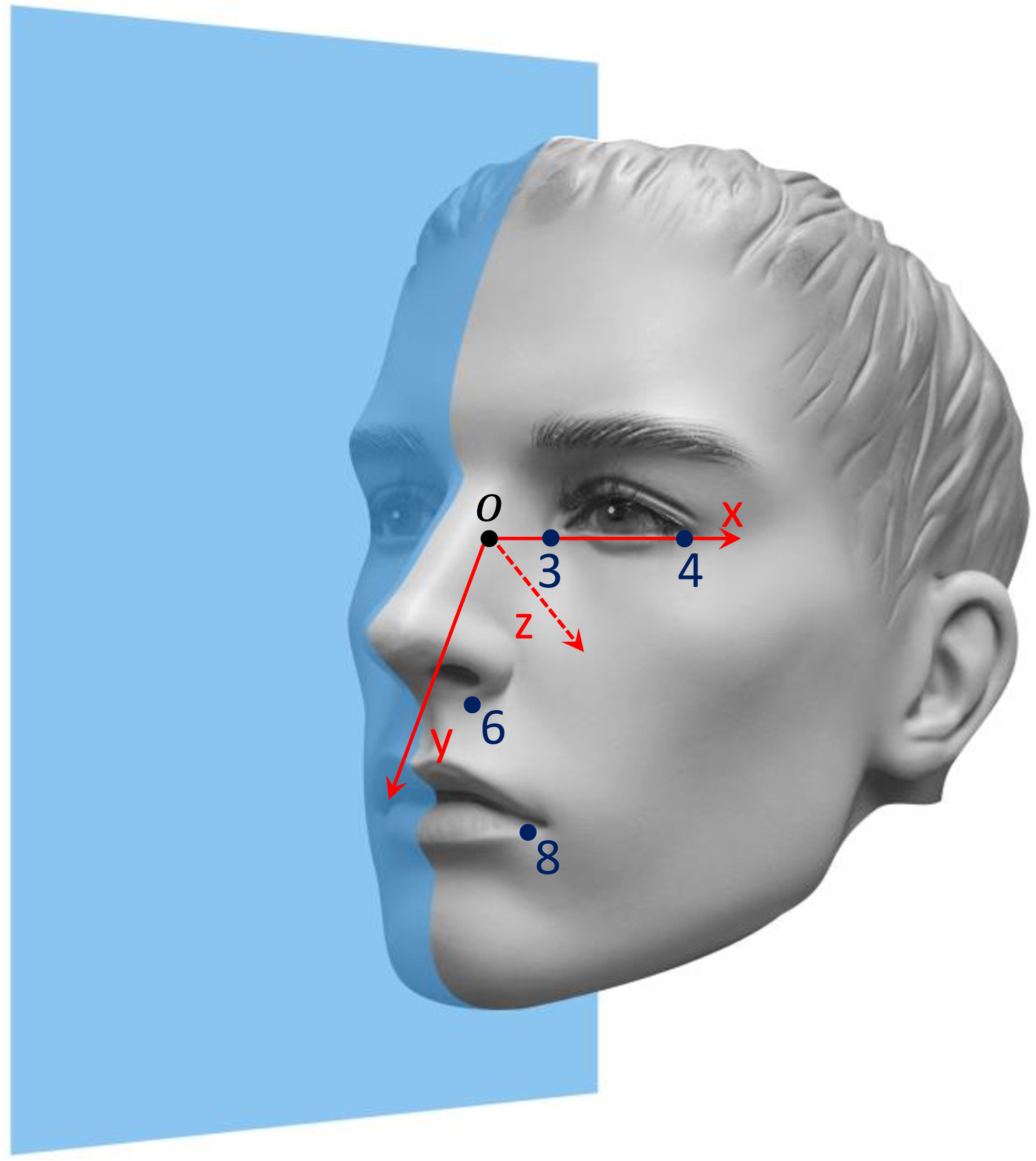
DriveAHead - A Large-Scale Driver Head Pose Dataset
Anke Schwarz*, Monica Haurilet*, Manuel Martinez, Rainer Stiefelhagen
CVPRW on Computer Vision in Vehicle Technology
(CVVT
Oral),
Honolulu, Hawaii, USA, 2017.
[paper]
[data]
[bibtex]
[abstract]
[website]
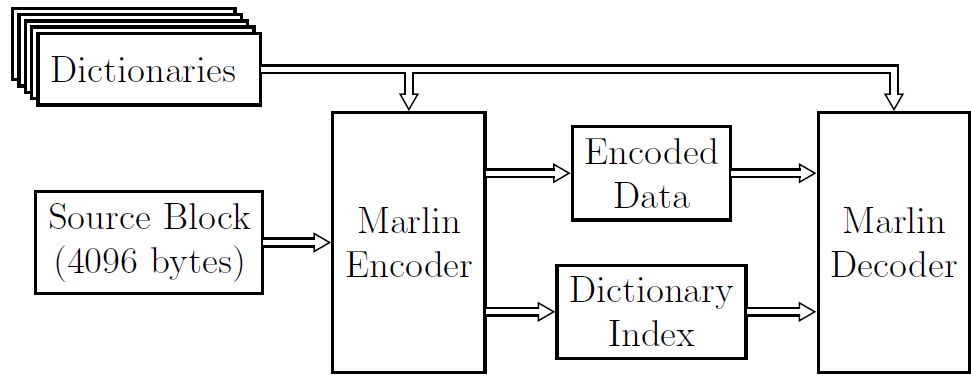
Marlin: A High Throughput Variable-to-Fixed Codec using Plurally Parsable Dictionaries
Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen and Joan Serra-Sagrista
Data Compression Conference
(DCC
Oral),
Snowbird, Utah, USA, 2017.
[paper]
[bibtex]
[abstract]

Naming TV Characters by Watching and Analyzing Dialogs
Monica-Laura Haurilet, Makarand Tapaswi, Ziad Al-Halah and Rainer Stiefelhagen
IEEE Winter Conference on Applications of Computer Vision
(WACV),
Lake Placid, NY, USA, 2016.
[paper]
[bibtex]
[abstract]
[poster]
[slides]
[data]
Thesis
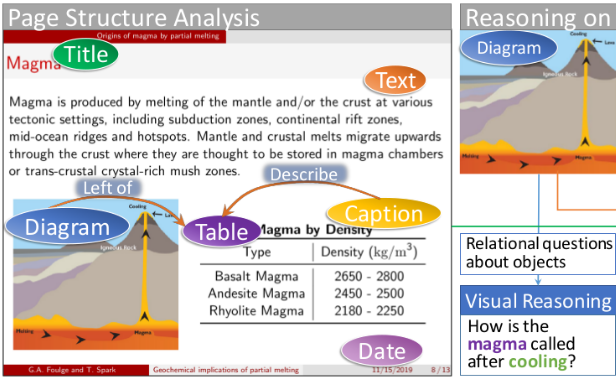
High-level Understanding of Visual Content in Learning Materials through Graph Neural Networks
Monica Haurilet
Dissertation, Karlsruhe Institute of Technology, 2020.
[coming soon]
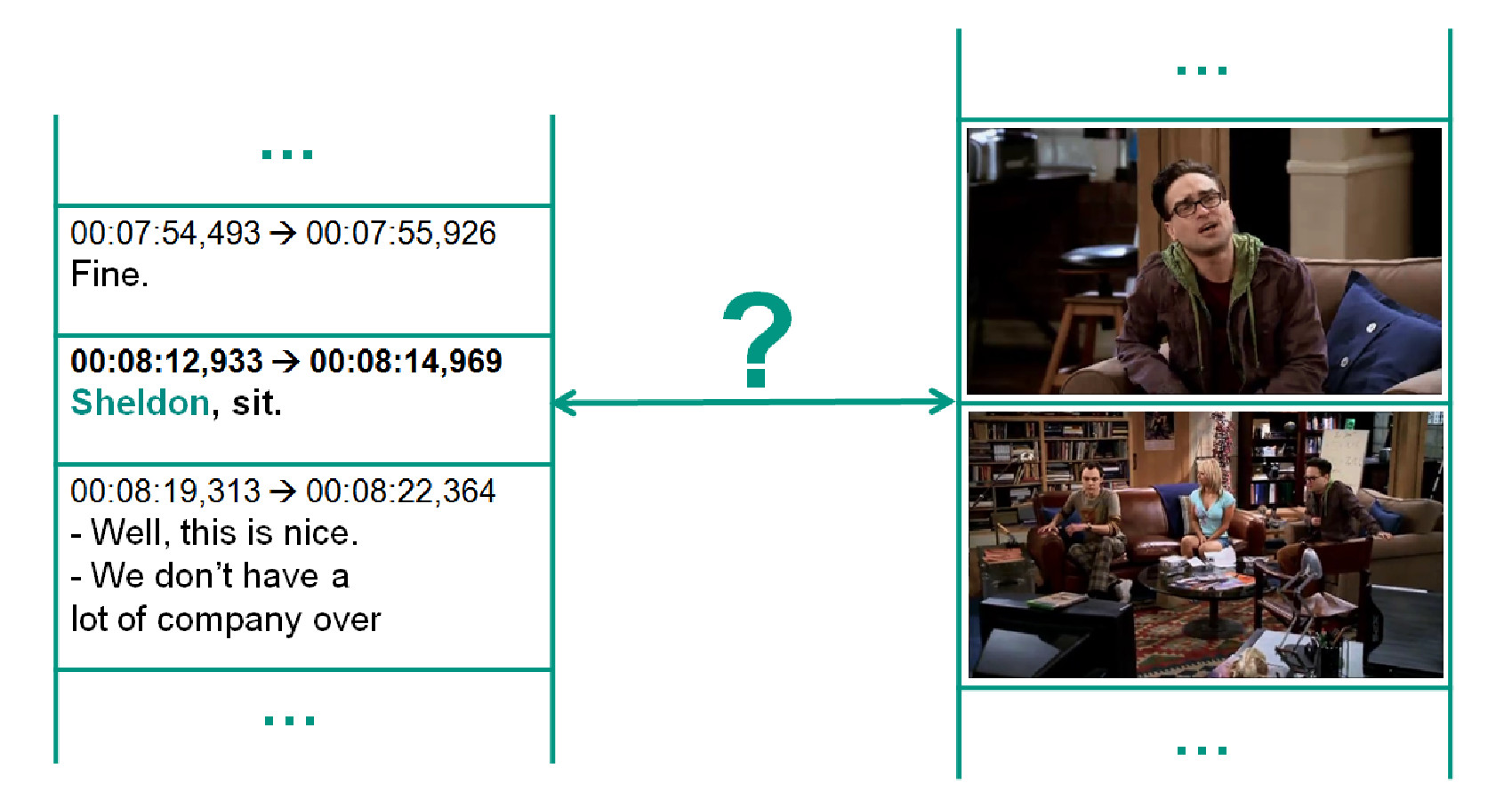
Completely Unsupervised Person Identification in TV-Series using Subtitles
Monica Haurilet
Master Thesis, Karlsruhe Institute of Technology, 2015.
[thesis]